

ตั้งแต่แรกเริ่มของการใช้คอมพิวเตอร์ ผมก็คุ้นชินกับการใช้ Google ในการค้นหาข้อมูลมาจนถึงปัจจุบัน จึงเกิดคำถามขึ้นว่า แล้ว Search Engine ก่อนหน้า Google มันมีวิวัฒนาการอย่างไรบ้าง วันนี้ผมจะพาเพื่อน ๆ ไปทำความรู้จักบรรพบุรุษของเว็บไซต์ค้นหาข้อมูลทั้งหลายกันครับ
สามกษัตริย์ Archie, Veronica และ Jughead จุดเริ่มต้นของ Search Engine
จริง ๆ มันมียุคก่อน Archie อีกนะ แต่ในที่นี้ผมขอยกให้ Archie เป็นรูปแบบของ Search engine รุ่นแรกที่สามารถค้นหาแบบสาธารณะได้ โดยการพัฒนา Archie เริ่มต้นในช่วงปี 1990 ที่การค้นหาข้อมูลจำนวนมากบนเซิร์ฟเวอร์ต้องกรความรวดเร็วมากขึ้น ประกอบกับอินเทอร์เน็ตเริ่มเข้ามามีบทบาทในกลุ่มองค์กรมากขึ้น
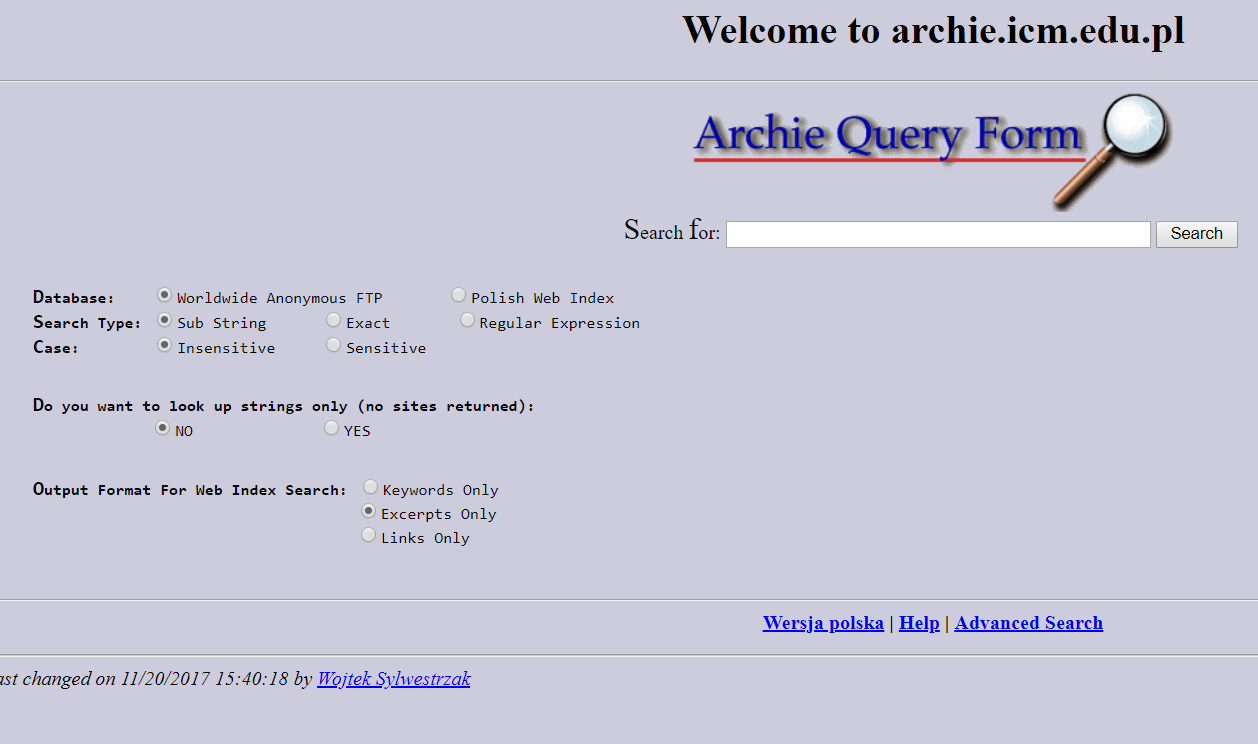
Archie ถูกทำขึ้นเพื่อการค้นหาให้มีการค้นหาไฟล์ต่าง ๆ บนเซิร์ฟเวอร์ FTP ที่เข้าร่วม ซึ่งข้อมูลที่ค้นหาได้จะออกมาในลักษณะลิสต์รายการเหมือนที่เราเจอในการเข้าถึง FTP อย่างที่คุ้นเคยนั่นแหละ จากนั้นไม่นานก็มีระบบที่คล้าย ๆ กันเปิดตัวตามมา นั่นคือ Veronica
Veronica จะแตกต่างจาก Archie ตรงที่มีการใช้เซิร์ฟวเอร์กลางเป็น Gopher ซึ่งดีกว่าการใช้ FTP โดยให้การค้นหาที่รวดเร็วกว่า แต่ในขณะเดียวกันบางคนบอกว่ามันมีข้อจำกัดเยอะ ลักษณะการค้นหาของระบบ Gopher ให้นึกถึงการใช้ Windows File Manager (Explorer)
ทีนี้ Gopher แบบดั้งเดิมมันจะต้องเปิดเมนูและซับเมนูขึ้นมาต่าง ๆ มากมายทำให้เกิดความล่าช้า Veronica จึงจัดทำผังไฟล์ใหม่ เพื่อให้เกิดการค้นหาได้อย่างรวดเร็วกว่าเซิร์ฟเวอร์แบบดั้งเดิมนั่นเองครับ ส่วน Jughead ก็ใช้เซิร์ฟเวอร์ Gopher เช่นเดียวกัน การค้นหาข้อมูลจะคล้ายกับ Veronica แต่จะไม่สามารถเพิ่มเซิร์ฟเวอร์ย่อยเข้ามาในระบบได้ ถึงแม้จะมีคำสั่งพิเศษบางอย่างที่ช่วยค้นหาข้อมูลได้ดีกว่า Veronica แต่ในทางปฏิบัติจะไม่นิยมเท่ากับรุ่นพี่นั่นเองครับ

ทีนี้ปัญหาหลัก ๆ ของ Archie, Veronica และ Jughead ที่ไม่อาจไม่ตอบโจทย์ได้ดีเหมือน Search engine ปัจจุบัน คืออย่างแรกพวกมันไม่สามารถค้นหาข้อมูล จากเซิร์ฟเวอร์นอกเหนือจากที่บรรจุลงในฐานข้อมูลระบบได้ (คือถ้าเซิร์ฟเวอร์ย่อยไม่ถูกนำเข้ามาในระบบ มันจะค้นไม่เจอ) อย่างที่สองคือพวกมันค้นหาได้เฉพาะส่วนของชื่อเรื่องและคำอธิบายสั้น ๆ แต่ไม่สามารถค้นหาข้อมูลจากคอนเทนต์ภายในได้ (ทำให้บางครั้งชื่อเรื่องตั้งอย่างหนี่ง แต่ภายในเป็นอีกเรื่องเลยก็มี)
นอกจากนี้ผู้พัฒนาเซิร์ฟเวอร์ Gopher มหาวิทยาลัยแห่งมลรัฐมินนีโซตา ดันเปลี่ยนใบอนุญาตจากเดิมที่เปิดให้ใช้งานได้ฟรี กลายเป็นแบบคิดค่าบริการสำหรับใครที่นำ Gopher ไปใช้ ประกอบกับช่วงปี 1993 เวิล์ดไวด์เว็บเริ่มเข้ามามีบทบาทมากขึ้น แถมยังใช้งานได้ฟรีไม่มีค่าใบอนุญาต สุดท้ายทำให้ระบบที่ทำงานบน Gopher ลดลงเรื่อย ๆ จนเหลือแค่บางคนที่นิยมใช้งานเป็นการพัฒนาโปรเจคเท่านั้นครับ
Search Engine ตัวแรกบน World Wide Web
แรกเริ่มของการใช้งาน WWW ยังไม่มี Search engine แน่นอนว่าช่วยแรก ๆ มันคงไม่ใช่งานยากที่คุณจะค้นหาข้อมูล เพราะมันยังมีข้อมูลอยู่ไม่มาก แต่หลังจากการล่มสลายของ Gopher ทำให้ WWW ได้รับความนิยมมากขึ้น แนวคิดการสร้าง Search engine ขึ้นมาใช้งานจึงต้องการคุณสมบัติ ดังนี้
– Web Crawler: สามารถค้นหาข้อมูลจากเว็บไซต์ต่าง ๆ รวมถึงข้อมูลภายในคอนเทนต์ได้ด้วยตนเอง
– Indexer: จัดทำดัชนีของเว็บไซต์ต่าง ๆ ขึ้นให้มีหมวดหมู่ที่เป็นระบบมากขึ้น (เหมือนดัชนีท้ายเล่มของหนังสือหนา ๆ)
– Search: ดัชนีข้อมูลที่จัดคำขึ้นตามคำค้น จะต้องเข้ากันได้กับเครื่องมือที่ใช้ค้นหา เพื่อให้ผลลัพธ์ที่ตรงตามต้องการ

แน่นอนว่าเมื่อพิจารณาจากกฎทั้งสามข้อแล้ว Search engine ยุคแรกไม่ตอบโจทย์ตามกฎข้างต้น อย่างไรก็ตาม Search engine ตัวแรกในยุคของ WWW คือ W3Catalog ยังไม่สามารถทำตามมาตรฐานทั้งสามข้อได้ โดยมันไม่สามารถค้นหาเว็บไซต์จากคำค้นได้เอง และไม่สามารถจัดทำดัชนีขึ้นมาได้ แต่จะมีการสร้างดัชนีชุดหนึ่งขึ้นมาโดยบอท แล้วนำไปใส่ไว้ในระบบ เมื่อมีการค้นหาตัวระบบจะวิ่งเข้าไปคุ้ยข้อมูลที่เข้ากันได้ แล้วสร้างลิสต์ที่เข้ากันได้ขึ้นมาใหม่แสดงให้ผู้ใช้เลือกลิ้งก์ที่ต้องการอีกที ในยุคนั้นมันก็พอใช้ได้นะครับ เพราะเว็บไซต์ยังมีไม่มากเท่าสมัยนี้
แต่ปัญหาของการใช้บอทคือเรื่องของการกินแบนด์วิดธ์มากเกินไปจนส่งผลต่อความเร็วในการค้นหา ทำให้ Aliweb ที่พัฒนาตามมาติด ๆ ได้เปลี่ยนการใช้บอทมาเป็นมนุษย์ ซึ่งทำหน้าที่เป็นเว็บมาสเตอร์คอยเพิ่มดัชนีเข้าไป แต่ทั้งสอง Search engine ยังเผชิญกับข้อจำกัดที่ว่า เว็บไซต์ใหม่ ๆ ที่ไม่ถูกจัดไว้ในดัชนีตั้งแต่แรก จะทำให้ค้นหาไม่เจอนั่นเองครับ

การทำดัชนีแบบ W3Catalog และ Aliweb เราเรียกว่า Web directories ซึ่งเป็นที่นิยมอย่างมากในช่วงนั้น แต่ Search engine รูปแบบ Web directories ที่ประสบความสำเร็จตกเป็นของ Yahoo! ซึ่งพัฒนาตามมาในปี 1994 ครับ
Yahoo! – Web directories ที่ประสบความสำเร็จมากที่สุด

เรายังอยู่กับ Search engine แบบ Web directories ในปี 1994 เว็บไซต์ Yahoo! ถือกำเนิดขึ้น โดยในช่วงแรกนั้น Yahoo! ทำหน้าที่เหมือนแหล่งรวบรวมเว็บไซต์ต่าง ๆ แบ่งตามหมวดหมู่ โดยจะให้ผู้ใช้เข้ามาค้นหาข้อมูลในดัชนีที่เตรียมไว้ แต่ความพิเศษของดัชนีนี้คือ บริษัทอนุญาตให้ผู้สร้างเว็บไซต์เพิ่มเว็บของตนเองเข้ามาในระบบได้ หรืออยากจะให้ขึ้นเป็นเว็บแรก ๆ และมีการโฆษณา ก็สามารถเลือกแบบเสียเงินได้ปีละ 300 ดอลลาร์
จากนั้น Yahoo! ได้พัฒนาให้เว็บมีความสะดวกมากขึ้น ด้วยการแสดงผลการค้นหาจากเว็บไซต์ Search engine ที่สามารถค้นหาและสร้างดัชนีของตัวเองได้ (ทำหน้าที่เป็นเว็บหน้าบ้านว่างั้นเถอะ แต่ตัวเองจะไม่ได้สามารถค้นหาและสร้างดัชนีเองได้)
จนกระทั่งในปี 2003 Yahoo! ได้เข้าซื้อเว็บไซต์ที่มีคุณสมบัติในการ Crawler และ Indexer หลายเจ้า จน Yahoo! Search ทำหน้าที่เป็น Search Engine แบบเต็มตัว และที่ทำให้ Yahoo! ต้องทำเช่นนี้ เพราะการมาถึงของ Google นั่นเองครับ
Crawler และ Indexer เว็บ Search Engine ยุคใหม่แบบครบสูตร
ต้นแบบของ Search Engine ที่สามารถทำการค้นหาข้อมูลได้เองนั้น คือ World Wide Web Wanderer หรือรู้จักกันในชื่อ Wanderer แต่มันไม่ได้ถูกนำมาใช้เพื่อการค้นหาข้อมูลแบบสาธารณะ เพราะฉะนั้นจึงขอเริ่มต้นด้วย JumpStation
JumpStation

เว็บนี้ถูกสร้างขึ้นในปี 1993 โดย Jonathan Fletcher ซึ่งได้ชื่อว่าเป็นบิดาแห่งการค้นหาข้อมูลออนไลน์ยุคใหม่ เขาเริ่มพัฒนาโดยใช้เซิร์ฟเวอร์เล็ก ๆ ของมหาวิทยาลัยสตาร์ลิง เว็บไซต์ JumpStation สามารถค้นหาชื่อเรื่องและข้อความสำคัญของเว็บไซต์ที่ผู้ใช้ต้องการ แล้วนำมาจัดทำเป็นดัชนีได้อย่างรวดเร็ว
ภายในระยะเวลาไม่ถึงปี JumpStation สามารถทำดัชนีเก็บไว้ได้ถึง 275,000 เรื่อง แน่นอนว่า Fletcher เองก็อยากขยับขยายเซิร์ฟเวอร์ให้ใหญ่ขึ้น แต่มหาวิทยาลัยปฏิเสธการให้เงินสนับสนุน เว็บไซต์จึงต้องปิดตัวลงอย่างน่าเสียดาย
Lycos
Lycos เป็นโปรเจคที่ถูกสร้างขึ้นในปี 1994 ก่อนที่จะดังเป็นพลุแตกในปี 1999 โดยมีผู้ใช้จำนวนมากตั้งไว้เป็นหน้าแรกของเบราว์เซอร์ เพื่อเริ่มต้นค้นหาข้อมูลครับ
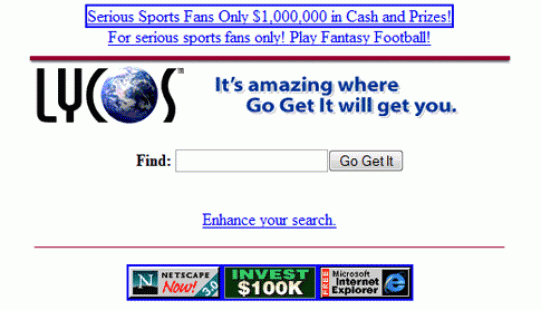
สิ่งที่ Lycos แตกต่างจาก Search Engine เจ้าอื่น คือเว็บไซต์จัดเป็นหนึ่งในการลงทุนทางธุรกิจของบริษัทที่คิดค้น มันสามารถทำเงินได้อย่างรวดเร็ว เจ้าของจึงมีเงินลงทุนเพื่อเพิ่มประสิทธิภาพในการทำงานของมัน ว่ากันว่าภายในระยะเวลาเพียงสองปี Lycos สามารถสร้างดัชนีเว็บไซต์ได้มากถึง 60,000,000 เรื่องเลยทีเดียว
สุดท้ายเว็บไซต์ก็ผ่านการซื้อขายเปลี่ยนมือไปมา แต่ทุกวันนี้คุณยังสามารถเข้าใช้งานกันได้อยู่ที่เว็บ www.lycos.com
Excite
เว็บนี้คือ Search engine เจ้าแรกที่พัฒนาวิธีการหาความสัมพันธ์ของคำ และวิเคราะห์ด้านสถิติของคำเพื่อให้เกิดผลลัพธ์ที่ตรงกับคำค้นหาของผู้ใช้มากที่สุด

Excite มีประวัติที่น่าเสียดายอย่างหนึ่ง สมัยที่ Google สร้างใหม่ ๆ เจ้าของ Excite ได้รับข้อเสนอให้เข้าซื้อ Google ถึงสองครั้ง ! ในครั้งแรกถูกเสนอให้ซื้อในราคาล้านดอลลาร์ แต่หลังจากนั้นราคาก็ลดลงเหลือ 750,000 สุดท้าย Excite ไม่ยอมตอบรับดีลทั้งสอง นับว่าเป็นการตัดสินใจที่ผิดพลาดอย่างหนึ่ง (และทำให้เรามี Google จนถึงทุกวันนี้)
Excite ล้มละลายในปี 2001 หลังจาก Google เปิดตัวได้เพียง 4 ปี
Alta Vista

เว็บนี้ผมเคยเห็นในหนังสือเรียน Windows 95 ได้แนะนำให้ใช้ Alta Vista เป็นหน้าหลักในการค้นหาข้อมูล เว็บไซต์นี้ถูกสร้างขึ้นในช่วงสิ้นปี 1995 โดย Digital Equipment Corporation และกลายเป็น Search engine ที่ได้รับความนิยมอย่างมากในเวลาต่อมา
จุดเด่นของ Alta Vista คือการปรับปรุงข้อความที่ใช้ในการค้นหา ผู้ใช้สามารถพิมพ์คำง่าย ๆ หรือคำที่เป็นภาษาพูดในการค้นหาข้อมูล (แทนที่จะเป็นคำทางการยาก ๆ เพื่อให้ได้ผลลัพธ์ที่ถูกต้อง) แถมยังมีการใช้คำสั่งประเภท Boolean เพื่อการค้นหา (ประมาณว่า ถูก/ผิด อะไรแบบนี้) เป็นครั้งแรกอีกด้วย
สุดท้าย Alta Vista ได้กลายเป็นส่วนหนึ่งในเครือของ Yahoo! ในเวลาต่อมา
Ask Jeeves
เชื่อว่าหลายคนที่ชอบโหลดโปรแกรมแชร์แวร์จากอินเทอร์เน็ต จะต้องเจอการติดตั้งหน้าแรก Ask.com ไว้ในเบราว์เซอร์ด้วยอย่างแน่นอน ใช้แล้วครับ ในปี 1996 ต้นฉบับของ Ask.com ถือกำเนิดขึ้นในชื่อ Ask Jeeves

จุดขายของ Ask Jeeves คือการค้าหาข้อมูลในลักษณะ ถาม-ตอบ อีกทั้งยังใช้อัลกอริธึมในการค้นหาเรียกว่า ExpertRank ซึ่งเป็นการให้คะแนนความนิยมของเว็บไซต์ ด้วยการตรวจสอบ backlink ที่โยงมาหาเว็บไซต์นั้น ถ้าเว็บนั้นมี backlink มาเยอะ ก็จะได้ลำดับที่สูงกว่า
ยกตัวอย่างเช่น บทความของผมเรื่อง SSD ในเว็บ Extreme IT โอ้โหเขียนดีมาก คนเลยขอยืมเนื้อหาไปใช้จากเว็บอื่น ๆ นับร้อย และมีการอ้างอิงลิ้งก์ต้นทางของผม นั่นทำให้เวลา ExpertRank มาตรวจสอบจะพบ backlink โยงมาที่บทความผมเยอะมาก ดังนั้นเวลาใครค้นหาคำว่า SSD จะเจอเว็บบทความของผมก่อนเว็บอื่น ๆ
กลับมาที่ Ask สุดท้ายแล้วบริษัทได้ลดความสำคัญของ Search engine ไป (ถึงว่ามันหายไปไหน ช่วงหนึ่งมันบูมมากเลย เพราะมันฝังลงเบราว์เซอร์แถมเอาออกยากมาก) และโฟกัสกับงานฐานข้อมูลแทนครับ
MSN Search

จุดเริ่มต้นของ Bing เริ่มจาก MSN Search ในปี 1998 ซึ่งได้ให้การค้นหาทั้งข้อมูลทั่วไป จนถึงบริการข่าวสารต่าง ๆ ตามแบบฉบับที่หลายคนน่าจะเคยพบเห็น จนปี 2004 มันถูกเปลี่ยนชื่อเป็น Windows Live Search และได้ชื่อ Bing ในปี 2009
MSN Search ต้องพบกับเรื่องน่าสงสารอย่างที่สุด เพราะในปีเดียวกันนั้นเอง Google ได้ถือกำเนิดขึ้น และกลายเป็นเจ้าพ่อแห่งวงการในเวลาอันรวดเร็ว
ต้องยอมรับว่า Bing เองเป็นคู่แข่งเจ้าเดียวที่น่าจะสมน้ำสมเนื้อกับ Google แต่จากประสบการณ์ส่วนตัวที่ผมเคยใช้งานพบว่ามันค้นข้อมูลยังไม่ตรงเท่ากับ Google นะ

จริง ๆ หลังจาก Google แล้วยังมี Search engine เปิดตัวอยู่บ้างแต่ก็ไม่ได้รับความนิยมเท่า ผมว่าส่วนหนึ่งที่ทำให้ Google ประสบความสำเร็จ มาจากหน้าตาของเว็บไซต์ที่เน้นความเรียบง่าย เมื่อเทียบกับเจ้าอื่น ๆ อีกทั้งระบบ PageRank ที่คล้ายกับ ExpertRank ของ Ask ทำออกมาได้ดีมาก ผลการค้นหาโดยส่วนใหญ่จึงตรงกับความต้องการของผู้ใช้งาน และทำให้ Google กลายเป็นบริษัท IT ที่มีอิทธิพลเจ้าหนึ่งเลยทีเดียว
แล้วคุณล่ะ เคยใช้ Search engine ตัวไหนมาบ้าง ลองบอกเล่าประสบการณ์กันได้ในคอมเมนต์เลยนะครับ
ขอขอบคุณข้อมูลจาก
https://www.whoishostingthis.com/resources/history-search-engines/
https://www.seomechanic.com/complete-history-search-engines/
You must be logged in to post a comment.